内部资料,请扫码登录
pigcloud
私有模型接入要求
PIG AI 支持通过在线配置接入私有化(ollama/vllm)模型,部署前请确保满足以下基础要求:
硬件资源:使用专业级GPU服务器,CPU不适用(两个并发推理 100%宕机) 显存要求:根据模型规模需预留充足VRAM(32B模型建议48G+,70B模型建议80G+) 生产环境:推荐使用NVIDIA A/H及以上专业计算卡,消费级显卡可能无法满足持续推理需求
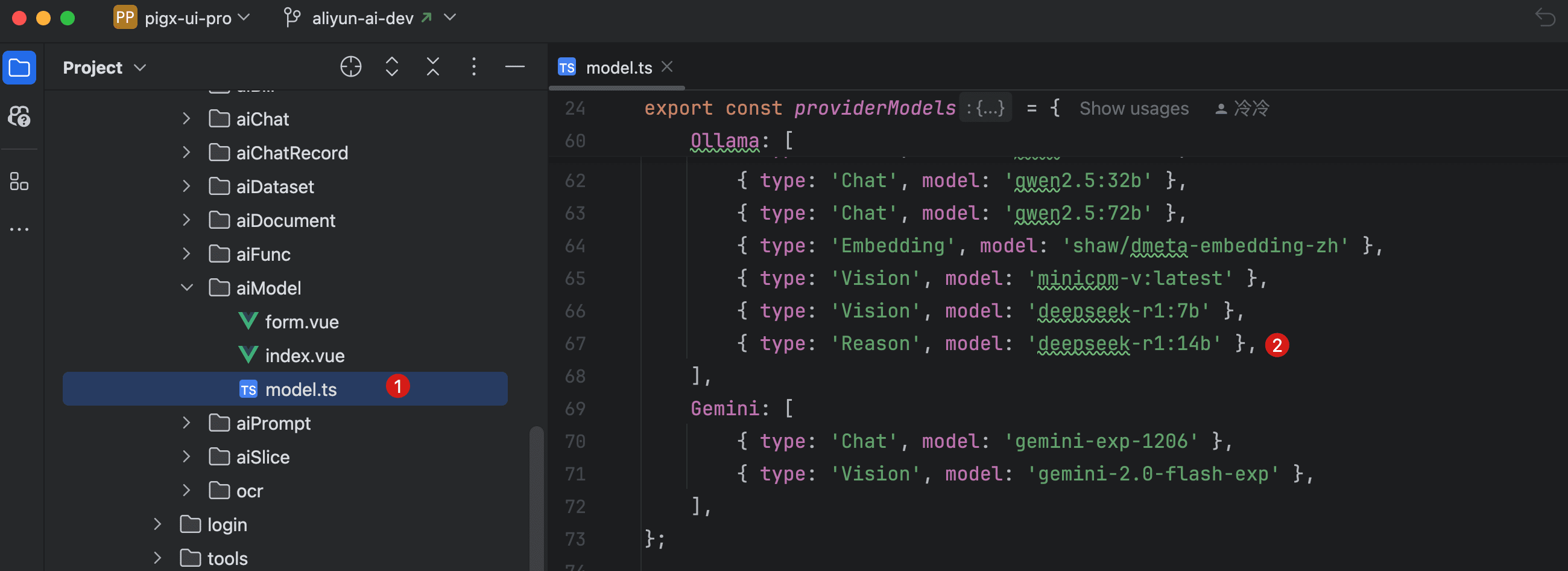
| 模型类型 | 模型名称 | 说明 |
|---|---|---|
| 聊天模型 | qwen2.5:72b | 72b参数量聊天模型,更准确需要更多资源 |
| 推理模型 | deepseek-r1:32b | R1 推理模型 |
| 向量模型 | bge-m3:latest | |
| 视觉模型 | minicpm-v:latest |
# 安装 ollama
- 下载 ollama 安装包 (opens new window) 请注意,ollama 版本需要 0.5.0 +
-【可选】配置 ollama 对外服务 (opens new window) ,默认情况下 ollla 默认只允许本地 11434 端口访问,需要配置 ollama 对外服务。
systemctl edit ollama.service
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
systemctl daemon-reload
systemctl restart ollama
# 运行私有模型
# 聊天模型,70b 代表参数集合数量,越大越准确,但是消耗资源越多
ollama run qwen2.5:72b
# 推理模型 R1 模型
ollama run deepseek-r1:32b
# 向量模型
ollama run bge-m3:latest
# 视觉模型
ollama run minicpm-v:latest
请注意运行 70b 模型为生产级模型,需要 GPU 80G+ 的显存,无法在普通 CPU 条件推理,模型推理速度(可以理解为提问响应速度)取决于硬件配置。
如下图: 两块 (A6000 + 48GB)

# 模型接入
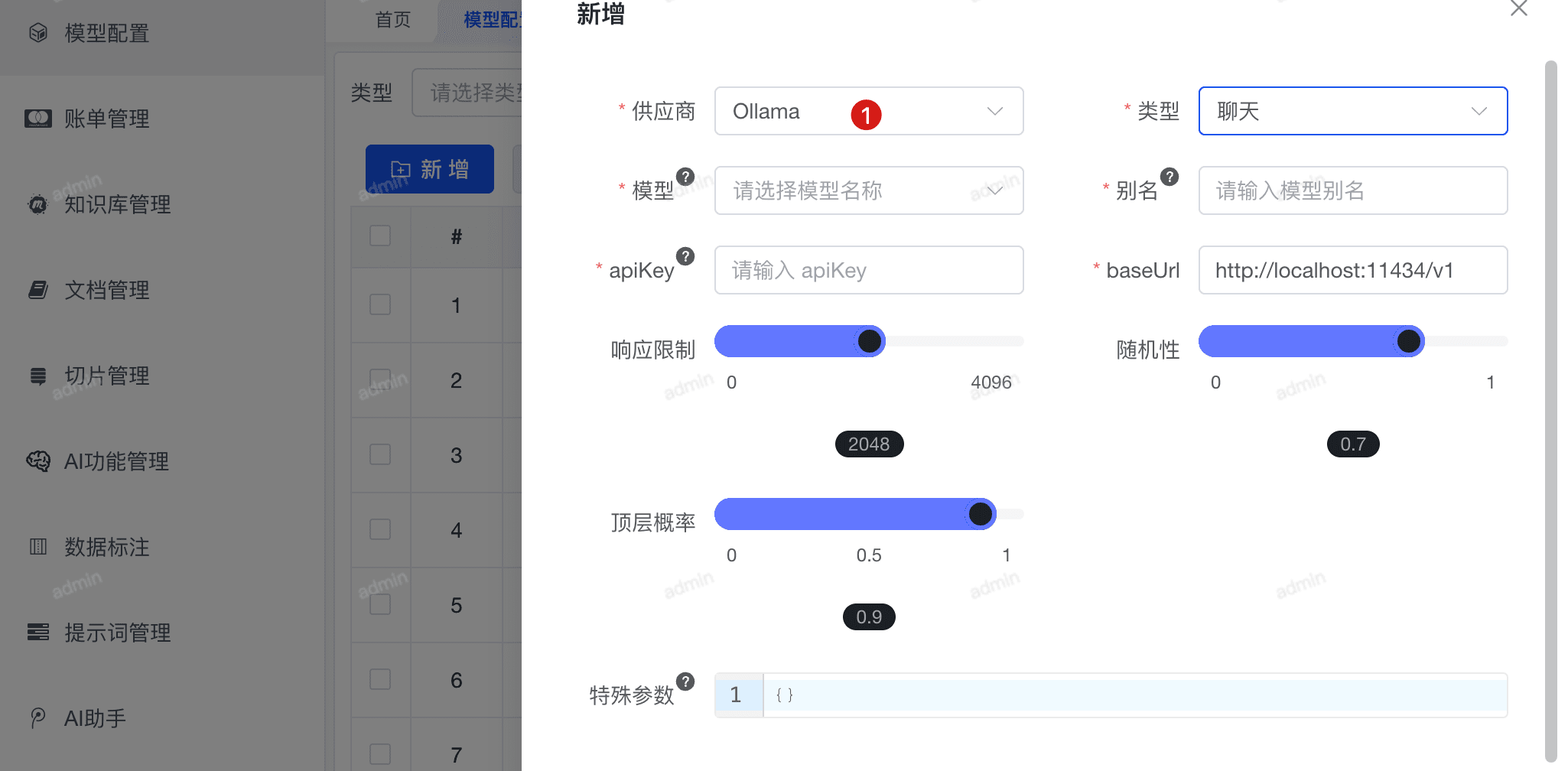
请注意配置的模型和如上 ollama 运行时模型名称一致,否则无法正常调用。
- 模型配置 > 新增模型
- 供应商:选择 Ollama
- 类型:根据需求选择聊天或推理模型
- 模型名称:选择已在 Ollama 运行的模型, 如 PIG AI 前端没有此模型选项可以输入添加